






什么是画面实时识别
画面实时识别,也称为实时图像识别或实时视频分析,是一种利用计算机视觉技术,对视频流或静态图像进行快速分析,以实时检测和识别其中的物体、场景或行为的技术。这项技术广泛应用于安防监控、智能交通、医疗诊断、工业自动化等领域,其核心在于能够迅速处理大量的图像数据,并提供实时的反馈。
技术原理
画面实时识别技术基于深度学习算法,特别是卷积神经网络(CNN)的应用。这些神经网络通过大量的图像数据进行训练,学习识别图像中的特征,如颜色、形状、纹理等。在实时识别过程中,算法会快速对输入的图像进行处理,提取关键特征,并利用这些特征进行分类和识别。
以下是画面实时识别技术的主要步骤:
图像预处理:对输入的图像进行缩放、裁剪、灰度化等处理,以提高识别效率和准确性。
特征提取:使用CNN等深度学习模型从图像中提取特征。
分类识别:根据提取的特征,将图像中的物体或场景分类为预定义的类别。
结果输出:将识别结果以文本、图形或声音等形式输出,供用户或系统进一步处理。
应用场景
画面实时识别技术在各个领域都有广泛的应用,以下是一些典型的应用场景:
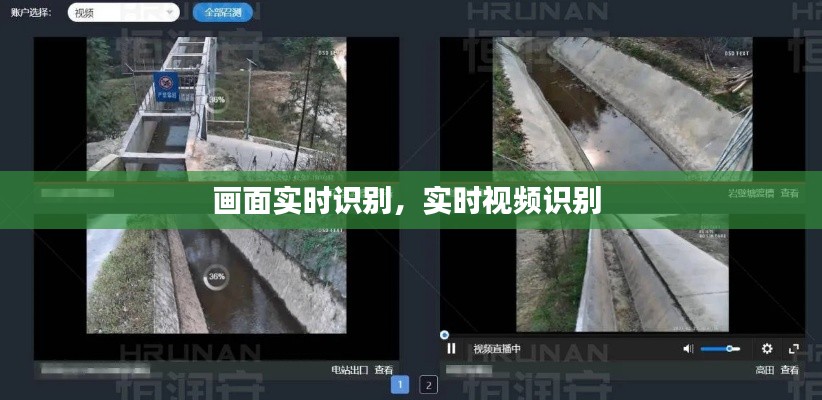
安防监控:实时监控公共场所,识别可疑人物或行为,提高安全防范能力。
智能交通:识别交通违法行为,如闯红灯、逆行等,提高交通管理效率。
医疗诊断:辅助医生进行疾病诊断,如皮肤癌检测、肿瘤检测等。
工业自动化:实时检测生产线上的产品质量,提高生产效率和产品质量。
零售业:分析顾客行为,优化商品陈列和促销策略。
挑战与未来发展趋势
尽管画面实时识别技术取得了显著的进展,但仍面临一些挑战:
计算资源:深度学习模型通常需要大量的计算资源,尤其是在实时处理高分辨率图像时。
数据质量:图像质量、光照条件、背景干扰等因素都会影响识别的准确性。

隐私保护:实时识别技术可能会涉及个人隐私问题,需要采取相应的保护措施。
未来发展趋势包括:
边缘计算:将计算任务从云端转移到边缘设备,减少延迟并提高实时性。
模型压缩:通过模型压缩技术减小模型大小,降低计算资源需求。
多模态融合:结合图像、声音、文本等多种数据源,提高识别的准确性和鲁棒性。
隐私保护技术:开发新的隐私保护技术,确保用户数据的安全和隐私。
结论
画面实时识别技术作为计算机视觉领域的重要分支,正逐渐改变着我们的生活和工作方式。随着技术的不断进步和应用的深入,我们可以期待画面实时识别技术在未来发挥更大的作用,为社会带来更多的便利和效益。
转载请注明来自青州金山泉水处理设备有限公司,本文标题:《画面实时识别,实时视频识别 》




 鲁ICP备18013447号-2
鲁ICP备18013447号-2