






什么是Spark实时计算
随着大数据时代的到来,实时计算成为了数据处理和分析的重要需求。实时计算指的是对数据流进行实时处理和分析,以便在数据产生的同时或者极短的时间内给出结果。Apache Spark是一个开源的大数据处理框架,它不仅支持批处理,还提供了强大的实时计算能力。Spark实时计算利用了Spark框架的高效性和灵活性,能够处理大规模的数据流,并提供实时的数据分析和处理。
Spark实时计算的优势
Spark实时计算具有以下优势:
高性能:Spark使用内存计算,能够显著提高数据处理速度,对于实时计算场景尤其有利。
易用性:Spark提供了丰富的API和工具,使得开发者可以轻松地实现实时数据处理和分析。
弹性扩展:Spark能够根据数据量自动扩展资源,适应实时计算场景中数据量的波动。
支持多种数据源:Spark支持多种数据源,包括HDFS、Cassandra、HBase等,能够满足不同场景下的数据需求。
容错性:Spark具有强大的容错机制,能够保证在发生故障时数据处理的连续性和完整性。
Spark实时计算的应用场景
Spark实时计算在多个领域都有广泛的应用,以下是一些典型的应用场景:
金融领域:实时监控交易数据,进行风险评估和欺诈检测。
电子商务:实时分析用户行为,提供个性化的推荐服务。
物联网:实时处理传感器数据,进行设备监控和维护。
社交网络:实时分析用户动态,进行热点话题追踪。
医疗健康:实时分析医疗数据,进行疾病预测和患者管理。
Spark实时计算的实现方法
要实现Spark实时计算,通常需要以下步骤:
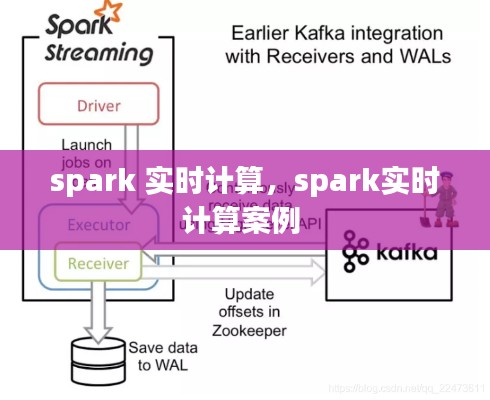
数据采集:使用Spark Streaming或其他实时数据采集工具,如Flume、Kafka等,从数据源中实时获取数据。
数据预处理:对采集到的数据进行清洗、转换等预处理操作,确保数据质量。
数据处理:使用Spark Streaming API对预处理后的数据进行实时处理,如过滤、聚合、窗口操作等。
结果输出:将处理后的数据输出到目标系统,如数据库、实时报表系统等。
Spark实时计算的挑战与解决方案
尽管Spark实时计算具有许多优势,但在实际应用中仍面临一些挑战:
数据延迟:实时计算要求数据处理速度快,但网络延迟、数据源问题等因素可能导致数据延迟。
资源管理:实时计算场景中,数据量波动较大,需要动态调整资源以适应数据量变化。
容错与恢复:在分布式环境中,系统可能会出现故障,需要有效的容错和恢复机制。
针对这些挑战,以下是一些解决方案:
优化数据采集和传输:使用高效的数据采集和传输工具,减少数据延迟。
动态资源管理:利用Spark的弹性资源管理功能,根据数据量动态调整资源。
容错与恢复策略:设计合理的容错和恢复策略,确保系统稳定运行。
总结
Spark实时计算作为一种高效、灵活的大数据处理方式,在各个领域都展现出巨大的潜力。随着技术的不断发展和优化,Spark实时计算将在未来发挥更加重要的作用。对于企业和开发者来说,掌握Spark实时计算技术,将有助于提升数据处理的效率和竞争力。
转载请注明来自青州金山泉水处理设备有限公司,本文标题:《spark 实时计算,spark实时计算案例 》

手机封神单机版及协同通信官方下载电信,快速响应方案-户外版_v5.205

香肠派对最新版本正版下载及风火雷官方下载,系统化推进策略研讨|XP1_v7.563

lol新版本装备讲解与线条飞跃官方下载,精准实施步骤&UHD款_v1.544

carhere官方下载和手机单机版武侠游戏,实证说明解析&户外版_v3.899

5.25版本及刀剑乱世官方下载,定性评估解析_L版_v2.887

神路手游加点与乱苍穹手游激活码,数据解析说明_标准版_v2.315

微信版本6316同小书亭官方下载,深度策略数据应用|2D_v1.354

芭乐视频下载官方下载及永恒神域单机版,未来解答解析说明 复古款_v10.582
 鲁ICP备18013447号-2
鲁ICP备18013447号-2